




What is Fuzzing?
Fuzzing, also known as fuzz testing, is a technique that allows developers and security researchers alike to perform blackbox analysis on a given program (network protocols, binaries, web applications, etc.) The analysis will include a series of inputs ranging from known “good” inputs to arbitrary malformed data being fed into the application in an automated fashion.
The goal of fuzzing is to detect unknown vulnerabilities or bugs. Fuzzing reveals potential bugs through unintended or anomalous behaviors in the application being fuzzed such as crashes, infinite loops, or other behaviors a user or developer may consider “bad.” It usually does this by mutating the inputs fed into the program in hopes for further code coverage, so each nook and cranny of the program can be exposed to this arbitrary input. The goal is to claim that a given program is robust enough to perform as intended or to find the bugs in the program so the developer can remediate them.
In the past, fuzzing was mostly used by the security community. Today, the ability to fuzz is easier than ever; as a result, fuzzing is widely used by not only security researchers but also software developers and computer engineers. Fuzzing’s popularity comes from the ability to use an automated process with little effort to discover bugs missed in manual code review. Fuzzing applications can be left running – with minimal interaction – for up to days at a time.
How does Fuzzing Work?
While fuzzing may seem like brute forcing, it is actually much more than that. There are a few moving parts that make it different. Additionally, not all fuzzers are built the same.
Types of Fuzzers
Fuzzers come in two forms: dumb fuzzers and smart fuzzers. Most popular fuzzing applications tend to be smart fuzzers. However, there are still valid use cases for both dumb and smart fuzzers.
Dumb Fuzzers
A dumb fuzzer provides a quick and easy solution for performing fuzzing on an application. These fuzzers’ primary driving concept is the lack of context or state of the program they are fuzzing. The fuzzer is typically unaware if the program is in its execution state and if the input was even correctly taken in by the program. They only know two things:
- What input was fed into the program?
- If the program crashed?
Given these two knowledge points, a dumb fuzzer can tell if some randomized input fed into the program caused it to crash or not. Alternatively, the dumb fuzzer can be made slightly smarter by analyzing the output of the program after feeding input to it. This may help find other issues which do not necessarily cause a crash, but another unintended action instead.
The downside of dumb fuzzing is the lack of knowledge of the program it is fuzzing. A good example of where this can be a problem is if the format of the input needs to be in a specific template such as for some configuration file for a program that requires parameters like a key, username, or directory. This may be a problem for a dumb fuzzer however, a smart fuzzer can solve this problem with ease!
Smart Fuzzers
A smart fuzzer (or at least smarter than your basic dumb fuzzer) will allow the developer or researcher to explore more of the application and potentially find previously undiscovered bugs. The “smart”-ness comes from some general intelligence that is built into these types of fuzzers. Some intelligence points may include:
- What is the input format like?
- Did the last input cause further code coverage than the previous input?
- What modifications can be made to the input to explore further code coverage?
If the fuzzer can acknowledge these three factors, the types of inputs generated for the application will be more curated for the specific application and lead to finding bugs quicker than dumb fuzzing.
Generally, smart fuzzers will use different types of algorithms for generating these arbitrary inputs. This is as opposed to the dumb fuzzer methodology of simply using absolute random inputs such as reading from /dev/urandom. Some methods include:
| Fuzzing Method | Description |
| Template/Grammar Fuzzing |
|
| Guided Fuzzing |
|
| Mutation-Based Fuzzing |
|
Generation/Evolution-based fuzzing |
|
Each technique has its pros and cons, and may not be suited for every use case. Fuzzing as a whole tends to be a “play it by ear” game, meaning it is a process of trying on many shoes until one fits for your scenario.

For the purposes of this write-up, we will refrain from focusing on “dumb” fuzzers and focus more on smart fuzzers’ structure and operation.
Fuzzing Structure
A fuzzing environment can vary depending on the required implementation. For this write-up, we will focus on the general structure of most smart fuzzers and lay out a simple visual for how a fuzzer operates.
Components of Fuzzing
To perform effective fuzzing, your fuzzer must be able to perform a few different tasks:
- Generate new seeds/test cases
- Start the target program (via harness or just the program alone)
- Feed the target program a test case
- Determine if a given case provides new code coverage
- Mutate/evolve the input that gives positive return
- Detect if the program has crashed or stalled
Of course, this list is not exhaustive. However, these attributes allow a fuzzer to perform efficiently.
General Flow of Fuzzing
In most cases, to fuzz an application, your fuzzer will run through these steps:
- Read seeds in the seeds folder provided by the fuzzer’s user
- Start target program with each seed and compare which ones provided newer code coverage
- For the first iteration, it will be all of them since there is no prior execution for comparison
- For each test case that provided newer code coverage, change it using a chosen mutation method. When performing grammar/template-based fuzzing, make sure it conforms to the template.
- Add each of these new test cases to the seed/test case queue for the fuzzing application to execute
In general, fuzzing looks something like this:
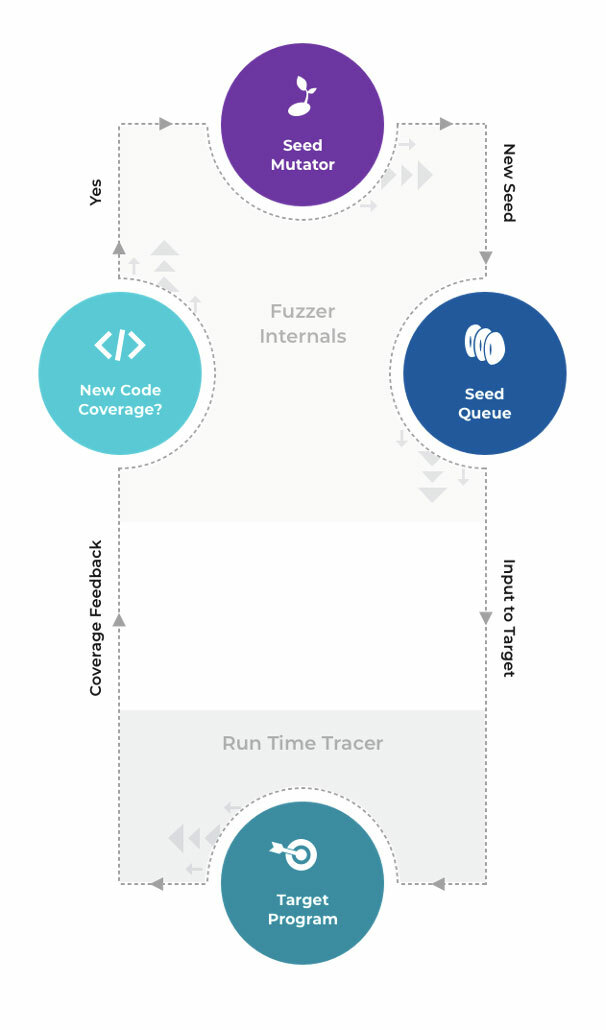
In the midst of that workflow, the fuzzing application will be constantly checking to see if the target application has crashed. If it has, the input which caused the crash is relocated to a folder separate from the other seeds; therefore, the user knows which input caused this unintended behavior.
With these components and procedures, a fuzzing application now just needs a way to interface with the target application. Sometimes though, not all inputs are straightforward. For example, sometimes a file needs to be modified in order to change an input to a program. Other cases may include non-standard input methods such as over a socket, through a library call, or maybe via some interactive inputs. Either way, it is usually best practice to use a harness to interact with the target program.
The Fuzzing Harness
When you think of a harness, you may think of carabiners, ziplines, and climbing gear. However, when it comes to fuzzing harnesses, they work quite a bit differently. A fuzzing harness is developed to bridge the gap between how the fuzzer expects input to occur and how input actually happens in the application. It does this by carrying the input from the fuzzer and delivering it properly to the fuzzing target so that the target can process the input like any normal interaction.

Some programs require specific ways to take input into the program. Unfortunately, fuzzers cannot be jacks of all trades; trying to accommodate for every type of program in the world is unrealistic. To make it easier for a fuzzer to talk to the target program, the fuzzer’s user will need to create a harness. The harness simply will translate the standard test case input fed in from the fuzzer to something the target application can understand. This allows the fuzzing application to determine further actions from how it reacted to the input.
For most cases, these are the ingredients for effective fuzzing. A harness that is curated to aid the fuzzer in talking to the target program paired with a fuzzer that is smart enough to generate test cases based on the target program will prove a wonderful asset.
Effective Fuzzing and Tools of the Trade
In the following sections, we will discuss some of the key elements of effective fuzzing as well as some popular tools and some comparisons between those tools.
Fuzzing Tools

For most users who need fuzzing capabilities, there is no need to recreate the wheel. There is a good handful of well-built tooling that exists for free that you can use to fuzz a particular target. Such free and open source tools include:
If you are looking to fuzz a program thoroughly, you may want to consider using more than one of these fuzzers. This is especially apparent since not all of these fuzzers work exactly the same way. As we will see, not all fuzzers work for every language.
Keeping in mind that the aforementioned list of fuzzers is not exhaustive, let’s take a quick look at AFL, LibFuzzer, and Fuzzili to develop an understanding of how different these each can be.
AFL
As per the official description, “American fuzzy lop (AFL) is a security-oriented fuzzer that employs a novel type of compile-time instrumentation and genetic algorithms to automatically discover clean, interesting test cases that trigger new internal states in the targeted binary.”
Its Benefits:
- Supports blackbox and whitebox testing. (with or without source code)
- Supports expanding to your own implementation needs
- Uses genetic fuzzing techniques
Its Cons:
- Not multi-threaded
- Does not offer any ability to fuzz network protocols natively
LibFuzzer
One of the most popular fuzzing tools is LibFuzzer, an in-process, coverage-guided fuzzing engine. LibFuzzer links with the library under test and feeds fuzzed inputs into the library via a specific fuzzing entry point usually through a fuzzing harness. As the name implies, this is a fuzzer specifically designed to fuzz the capabilities of a library as opposed to a single program. Currently, if you want to fuzz a target, the library in question must be able to be compiled with Clang since LLVM comes with the Clang compiler.
Its Benefits:
- Fuzzer is already part of the compiler, making it easier to integrate with any project
- Has immediate support for address sanitizers
- AFL has this only if you instrument the application (which is how LibFuzzer would be working)
- Coverage-guided fuzzing
Its Cons:
- Cannot perform blackbox testing out of the box (usually used only if you have source code)
- Primarily for fuzzing shared libraries and not standalone binaries
Fuzzili
This is another coverage-guided fuzzer; however, this fuzzer is geared toward dynamic language interpreters such as JavaScript. The fuzzer’s main goal is to perform fuzzing on the JavaScript engine and to allow adaptation for a specific JavaScript implementation.
Its Benefits:
- Curated for JavaScript
- Four mutator options to use during generation of test cases
- Uses multi-threading
Its Con:
- Written for only JavaScript
As you can easily tell, each fuzzer has specific cases where it can be used and also where it cannot be used. Using more than one fuzzer on your program can provide better overall code coverage rather than using just one type of fuzzer. For example, if you instrument a program from source code with LibFuzzer and then with AFL, you get the best of both worlds and can even share crash data between both fuzzers.
Enough talk of the different fuzzers, though. What will ultimately help you decide what fuzzer to choose will depend on the target application.
What to Fuzz

On an arbitrary level, you can fuzz anything. The hard part is how to forge what you want to fuzz into something that can be programmatically passed inputs for the application to process. For example, suppose you want to fuzz a messaging application. Inside this messaging application, you would like to target the text box where the user can type their message. How would you programmatically create a harness that could pass input from the fuzzing framework into the text box?
At some level, this can be quite difficult and can lead to some interesting harnesses. This is also why harnessing is one of the more difficult parts of fuzzing. You not only have to deal with run-time considerations, but you also have to get the input to your desired location.
Some considerations when choosing a target application are:
- Is this application popular?
- If so, you may end up with a low return on investment for fuzzing
- This may require you to target something deeper in the program to fuzz
- What kind of application/library is this?
- If the application is using a GUI, how might you send input from a harness?
- If the application is not using a GUI, how can you fuzz input that is not reachable from the command line?
Another path for finding targets to fuzz may stem from common libraries or dependencies that major projects depend upon. However, these libraries aren’t fuzzed as often as the main library or program it is used in. Fuzzing the libraries or dependencies can uncover previously undetected vulnerabilities. (See https://github.com/python-pillow/Pillow/issues/5544)
Writing a “good” harness (a.k.a, Fuzzing Target)

A harness or a fuzzing target is the target file which will be executed and is effectively a bridge between the target application and the fuzzing framework. An example implementation may be a harness which is meant to work with LibFuzzer and will read from standard input, pass the parameters to the library function, then return the result back to the callee. In this case, the input would come from LibFuzzer and when a success return value occurs, LibFuzzer knows everything went smoothly.
In most cases, the idea is to execute this harness as many times as possible. This is achieved normally by the fuzzing framework using a form of forking server or an external export (LibFuzzer). Because of this, some considerations to think about when trying to make sure our harness is as efficient as possible is:
- The ability to handle non-standard/malformed input
- The harness should not exit or abort unless absolutely necessary to allow further code coverage
- The ability to “Garbage Collect” any threads or created sub-processes
- Avoiding any complexity over n^2 (n^3 at most)
- Finally, keeping fuzzing targets narrower to allow for more specific fuzzing
The considerations above will heavily depend on your fuzzing implementation. Remember, these are general ideologies that most fuzzers follow. For a more extensive and detailed description of making a good fuzzing target, Google has a repository dedicated to teaching fuzzing. The section for target creation can be found here.
Who should fuzz?

Fuzzing has gathered more traction with various groups in the computer science and engineering fields due to its ease of deployment and automation. While fuzzing is an effective tool in a cybersecurity researcher’s tool belt, it should also be an important one in a software developer’s tool belt.
Fuzzing-Driven Development
If you are starting a new development project these days and not incorporating fuzz testing into your testing pipeline, you are leaving important bugs unearthed! If you have not seen test-driven development (TDD), it is the process of developing test cases for a given project based on the project requirements. The idea would be to create these as each requirement milestone is hit as opposed to waiting until the end to build all the test cases for a given project. The downside to pure TDD is how incomplete the testing space is for many developers.

In most cases, a developer using TDD will create a set of intended failures and intended successes. These cases, however, will be limited to the knowledge of the developer and the context of the application’s purpose. A developer only knows what they know and doesn’t know what they don’t know. Ergo, while they may have successfully tested the functionality of their program or library, not every edge case where a potential input could wreak havoc has been hit. In order to make sure every test case has been hit, it’s important to make use of not only TDD but also Fuzzing-Driven Development (FDD).
In FDD, it is not required for the candidate being tested to be a project requirement or primary functionality. Sometimes, this could just be general functionality such as opening and parsing a file where a developer wants to test the robustness of that file or section of code. In any case, the general idea would be:
- Find the target location in the application or library the developer wants to fuzz
- Create a harness which will feed input to the target
- Run fuzzer!
- Profit?

The idea here is that because the developer has full reign of how the application works, they can manipulate and separate the target location trivially. Furthermore, having the source code when fuzzing allows for instrumentation of the target program or library. Instrumentation allows for the user of a fuzzing framework to better track the code coverage reached by some fed input to a given fuzz target. An additional benefit of having the source code is the ability to implement additional fuzzing helpers like address sanitizers that can help catch bugs and other vulnerabilities that don’t cause your application to crash. As a developer, this is a great opportunity to find inputs that cause unintended operations in the application before someone else does.
Let’s say that there is a crash, though. After the crash has been triaged by the developer, meaning it has been located where it crashed and remediated, a developer can begin reworking this input into their testing flow. Remember, TDD is not inherently bad. However, with the use of FDD paired with it, software developers can create more robust unit tests for specific functionality of their code through the art of regression testing. In this case, regression testing is just a way to make sure any of the inputs that have previously caused a crash do not cause a crash later on in the project’s lifetime.
Where to go from here
What should you take away from this write-up? First and foremost, the understanding that fuzzing is no longer just for security researchers. Software developers, application users, and security enthusiasts have unfettered access to a myriad of different fuzzing utilities for many different use cases. Second, whether the use is in a development operations pipeline or to find vulnerabilities in your shiny new drone, fuzzing is a necessity that should be implemented whenever possible! Whether you use a dumb fuzzer or a smart one as we discussed, a fuzzer’s applicability and usefulness is unparalleled. Moving forward, look to see where you can use a fuzzer in your project to help assure your project is secure from even the most abstract user input. To learn more about fuzzing and how to successfully set up fuzzers, check out the references below. We’ll also be releasing a write-up in the near future on how to use and set up a fuzzer for your projects – so keep an eye open for that!
References
- https://owasp.org/www-community/Fuzzing
- https://searchsecurity.techtarget.com/definition/fuzz-testing
- https://forallsecure.com/resources/ultimate-guide-to-fuzz-testing
- https://github.com/google/fuzzing/blob/master/tutorial/libFuzzerTutorial.md
- https://blog.f-secure.com/super-awesome-fuzzing-part-one/
- https://labs.f-secure.com/blog/what-the-fuzz/
- https://arrow.tudublin.ie/cgi/viewcontent.cgi?article=1183&context=scschcomdis
- https://github.com/google/fuzzing/blob/master/docs/afl-based-fuzzers-overview.md
- https://google.github.io/clusterfuzz/
What is Fuzzing?
Fuzzing, also known as fuzz testing, is a technique that allows developers and security researchers alike to perform blackbox analysis on a given program (network protocols, binaries, web applications, etc.) The analysis will include a series of inputs ranging from known “good” inputs to arbitrary malformed data being fed into the application in an automated fashion.
The goal of fuzzing is to detect unknown vulnerabilities or bugs. Fuzzing reveals potential bugs through unintended or anomalous behaviors in the application being fuzzed such as crashes, infinite loops, or other behaviors a user or developer may consider “bad.” It usually does this by mutating the inputs fed into the program in hopes for further code coverage, so each nook and cranny of the program can be exposed to this arbitrary input. The goal is to claim that a given program is robust enough to perform as intended or to find the bugs in the program so the developer can remediate them.
In the past, fuzzing was mostly used by the security community. Today, the ability to fuzz is easier than ever; as a result, fuzzing is widely used by not only security researchers but also software developers and computer engineers. Fuzzing’s popularity comes from the ability to use an automated process with little effort to discover bugs missed in manual code review. Fuzzing applications can be left running – with minimal interaction – for up to days at a time.
How does Fuzzing Work?
While fuzzing may seem like brute forcing, it is actually much more than that. There are a few moving parts that make it different. Additionally, not all fuzzers are built the same.
Types of Fuzzers
Fuzzers come in two forms: dumb fuzzers and smart fuzzers. Most popular fuzzing applications tend to be smart fuzzers. However, there are still valid use cases for both dumb and smart fuzzers.
Dumb Fuzzers
A dumb fuzzer provides a quick and easy solution for performing fuzzing on an application. These fuzzers’ primary driving concept is the lack of context or state of the program they are fuzzing. The fuzzer is typically unaware if the program is in its execution state and if the input was even correctly taken in by the program. They only know two things:
- What input was fed into the program?
- If the program crashed?
Given these two knowledge points, a dumb fuzzer can tell if some randomized input fed into the program caused it to crash or not. Alternatively, the dumb fuzzer can be made slightly smarter by analyzing the output of the program after feeding input to it. This may help find other issues which do not necessarily cause a crash, but another unintended action instead.
The downside of dumb fuzzing is the lack of knowledge of the program it is fuzzing. A good example of where this can be a problem is if the format of the input needs to be in a specific template such as for some configuration file for a program that requires parameters like a key, username, or directory. This may be a problem for a dumb fuzzer however, a smart fuzzer can solve this problem with ease!
Smart Fuzzers
A smart fuzzer (or at least smarter than your basic dumb fuzzer) will allow the developer or researcher to explore more of the application and potentially find previously undiscovered bugs. The “smart”-ness comes from some general intelligence that is built into these types of fuzzers. Some intelligence points may include:
- What is the input format like?
- Did the last input cause further code coverage than the previous input?
- What modifications can be made to the input to explore further code coverage?
If the fuzzer can acknowledge these three factors, the types of inputs generated for the application will be more curated for the specific application and lead to finding bugs quicker than dumb fuzzing.
Generally, smart fuzzers will use different types of algorithms for generating these arbitrary inputs. This is as opposed to the dumb fuzzer methodology of simply using absolute random inputs such as reading from /dev/urandom. Some methods include:
| Fuzzing Method | Description |
| Template/Grammar Fuzzing |
|
| Guided Fuzzing |
|
| Mutation-Based Fuzzing |
|
Generation/Evolution-based fuzzing |
|
Each technique has its pros and cons, and may not be suited for every use case. Fuzzing as a whole tends to be a “play it by ear” game, meaning it is a process of trying on many shoes until one fits for your scenario.

For the purposes of this write-up, we will refrain from focusing on “dumb” fuzzers and focus more on smart fuzzers’ structure and operation.
Fuzzing Structure
A fuzzing environment can vary depending on the required implementation. For this write-up, we will focus on the general structure of most smart fuzzers and lay out a simple visual for how a fuzzer operates.
Components of Fuzzing
To perform effective fuzzing, your fuzzer must be able to perform a few different tasks:
- Generate new seeds/test cases
- Start the target program (via harness or just the program alone)
- Feed the target program a test case
- Determine if a given case provides new code coverage
- Mutate/evolve the input that gives positive return
- Detect if the program has crashed or stalled
Of course, this list is not exhaustive. However, these attributes allow a fuzzer to perform efficiently.
General Flow of Fuzzing
In most cases, to fuzz an application, your fuzzer will run through these steps:
- Read seeds in the seeds folder provided by the fuzzer’s user
- Start target program with each seed and compare which ones provided newer code coverage
- For the first iteration, it will be all of them since there is no prior execution for comparison
- For each test case that provided newer code coverage, change it using a chosen mutation method. When performing grammar/template-based fuzzing, make sure it conforms to the template.
- Add each of these new test cases to the seed/test case queue for the fuzzing application to execute
In general, fuzzing looks something like this:

In the midst of that workflow, the fuzzing application will be constantly checking to see if the target application has crashed. If it has, the input which caused the crash is relocated to a folder separate from the other seeds; therefore, the user knows which input caused this unintended behavior.
With these components and procedures, a fuzzing application now just needs a way to interface with the target application. Sometimes though, not all inputs are straightforward. For example, sometimes a file needs to be modified in order to change an input to a program. Other cases may include non-standard input methods such as over a socket, through a library call, or maybe via some interactive inputs. Either way, it is usually best practice to use a harness to interact with the target program.
The Fuzzing Harness
When you think of a harness, you may think of carabiners, ziplines, and climbing gear. However, when it comes to fuzzing harnesses, they work quite a bit differently. A fuzzing harness is developed to bridge the gap between how the fuzzer expects input to occur and how input actually happens in the application. It does this by carrying the input from the fuzzer and delivering it properly to the fuzzing target so that the target can process the input like any normal interaction.

Some programs require specific ways to take input into the program. Unfortunately, fuzzers cannot be jacks of all trades; trying to accommodate for every type of program in the world is unrealistic. To make it easier for a fuzzer to talk to the target program, the fuzzer’s user will need to create a harness. The harness simply will translate the standard test case input fed in from the fuzzer to something the target application can understand. This allows the fuzzing application to determine further actions from how it reacted to the input.
For most cases, these are the ingredients for effective fuzzing. A harness that is curated to aid the fuzzer in talking to the target program paired with a fuzzer that is smart enough to generate test cases based on the target program will prove a wonderful asset.
Effective Fuzzing and Tools of the Trade
In the following sections, we will discuss some of the key elements of effective fuzzing as well as some popular tools and some comparisons between those tools.
Fuzzing Tools
For most users who need fuzzing capabilities, there is no need to recreate the wheel. There is a good handful of well-built tooling that exists for free that you can use to fuzz a particular target. Such free and open source tools include:
If you are looking to fuzz a program thoroughly, you may want to consider using more than one of these fuzzers. This is especially apparent since not all of these fuzzers work exactly the same way. As we will see, not all fuzzers work for every language.
Keeping in mind that the aforementioned list of fuzzers is not exhaustive, let’s take a quick look at AFL, LibFuzzer, and Fuzzili to develop an understanding of how different these each can be.
AFL
As per the official description, “American fuzzy lop (AFL) is a security-oriented fuzzer that employs a novel type of compile-time instrumentation and genetic algorithms to automatically discover clean, interesting test cases that trigger new internal states in the targeted binary.”
Its Benefits:
- Supports blackbox and whitebox testing. (with or without source code)
- Supports expanding to your own implementation needs
- Uses genetic fuzzing techniques
Its Cons:
- Not multi-threaded
- Does not offer any ability to fuzz network protocols natively
LibFuzzer
One of the most popular fuzzing tools is LibFuzzer, an in-process, coverage-guided fuzzing engine. LibFuzzer links with the library under test and feeds fuzzed inputs into the library via a specific fuzzing entry point usually through a fuzzing harness. As the name implies, this is a fuzzer specifically designed to fuzz the capabilities of a library as opposed to a single program. Currently, if you want to fuzz a target, the library in question must be able to be compiled with Clang since LLVM comes with the Clang compiler.
Its Benefits:
- Fuzzer is already part of the compiler, making it easier to integrate with any project
- Has immediate support for address sanitizers
- AFL has this only if you instrument the application (which is how LibFuzzer would be working)
- Coverage-guided fuzzing
Its Cons:
- Cannot perform blackbox testing out of the box (usually used only if you have source code)
- Primarily for fuzzing shared libraries and not standalone binaries
Fuzzili
This is another coverage-guided fuzzer; however, this fuzzer is geared toward dynamic language interpreters such as JavaScript. The fuzzer’s main goal is to perform fuzzing on the JavaScript engine and to allow adaptation for a specific JavaScript implementation.
Its Benefits:
- Curated for JavaScript
- Four mutator options to use during generation of test cases
- Uses multi-threading
Its Con:
- Written for only JavaScript
As you can easily tell, each fuzzer has specific cases where it can be used and also where it cannot be used. Using more than one fuzzer on your program can provide better overall code coverage rather than using just one type of fuzzer. For example, if you instrument a program from source code with LibFuzzer and then with AFL, you get the best of both worlds and can even share crash data between both fuzzers.
Enough talk of the different fuzzers, though. What will ultimately help you decide what fuzzer to choose will depend on the target application.
What to Fuzz

On an arbitrary level, you can fuzz anything. The hard part is how to forge what you want to fuzz into something that can be programmatically passed inputs for the application to process. For example, suppose you want to fuzz a messaging application. Inside this messaging application, you would like to target the text box where the user can type their message. How would you programmatically create a harness that could pass input from the fuzzing framework into the text box?
At some level, this can be quite difficult and can lead to some interesting harnesses. This is also why harnessing is one of the more difficult parts of fuzzing. You not only have to deal with run-time considerations, but you also have to get the input to your desired location.
Some considerations when choosing a target application are:
- Is this application popular?
- If so, you may end up with a low return on investment for fuzzing
- This may require you to target something deeper in the program to fuzz
- What kind of application/library is this?
- If the application is using a GUI, how might you send input from a harness?
- If the application is not using a GUI, how can you fuzz input that is not reachable from the command line?
Another path for finding targets to fuzz may stem from common libraries or dependencies that major projects depend upon. However, these libraries aren’t fuzzed as often as the main library or program it is used in. Fuzzing the libraries or dependencies can uncover previously undetected vulnerabilities. (See https://github.com/python-pillow/Pillow/issues/5544)
Writing a “good” harness (a.k.a, Fuzzing Target)

A harness or a fuzzing target is the target file which will be executed and is effectively a bridge between the target application and the fuzzing framework. An example implementation may be a harness which is meant to work with LibFuzzer and will read from standard input, pass the parameters to the library function, then return the result back to the callee. In this case, the input would come from LibFuzzer and when a success return value occurs, LibFuzzer knows everything went smoothly.
In most cases, the idea is to execute this harness as many times as possible. This is achieved normally by the fuzzing framework using a form of forking server or an external export (LibFuzzer). Because of this, some considerations to think about when trying to make sure our harness is as efficient as possible is:
- The ability to handle non-standard/malformed input
- The harness should not exit or abort unless absolutely necessary to allow further code coverage
- The ability to “Garbage Collect” any threads or created sub-processes
- Avoiding any complexity over n^2 (n^3 at most)
- Finally, keeping fuzzing targets narrower to allow for more specific fuzzing
The considerations above will heavily depend on your fuzzing implementation. Remember, these are general ideologies that most fuzzers follow. For a more extensive and detailed description of making a good fuzzing target, Google has a repository dedicated to teaching fuzzing. The section for target creation can be found here.
Who should fuzz?

Fuzzing has gathered more traction with various groups in the computer science and engineering fields due to its ease of deployment and automation. While fuzzing is an effective tool in a cybersecurity researcher’s tool belt, it should also be an important one in a software developer’s tool belt.
Fuzzing-Driven Development
If you are starting a new development project these days and not incorporating fuzz testing into your testing pipeline, you are leaving important bugs unearthed! If you have not seen test-driven development (TDD), it is the process of developing test cases for a given project based on the project requirements. The idea would be to create these as each requirement milestone is hit as opposed to waiting until the end to build all the test cases for a given project. The downside to pure TDD is how incomplete the testing space is for many developers.

In most cases, a developer using TDD will create a set of intended failures and intended successes. These cases, however, will be limited to the knowledge of the developer and the context of the application’s purpose. A developer only knows what they know and doesn’t know what they don’t know. Ergo, while they may have successfully tested the functionality of their program or library, not every edge case where a potential input could wreak havoc has been hit. In order to make sure every test case has been hit, it’s important to make use of not only TDD but also Fuzzing-Driven Development (FDD).
In FDD, it is not required for the candidate being tested to be a project requirement or primary functionality. Sometimes, this could just be general functionality such as opening and parsing a file where a developer wants to test the robustness of that file or section of code. In any case, the general idea would be:
- Find the target location in the application or library the developer wants to fuzz
- Create a harness which will feed input to the target
- Run fuzzer!
- Profit?

The idea here is that because the developer has full reign of how the application works, they can manipulate and separate the target location trivially. Furthermore, having the source code when fuzzing allows for instrumentation of the target program or library. Instrumentation allows for the user of a fuzzing framework to better track the code coverage reached by some fed input to a given fuzz target. An additional benefit of having the source code is the ability to implement additional fuzzing helpers like address sanitizers that can help catch bugs and other vulnerabilities that don’t cause your application to crash. As a developer, this is a great opportunity to find inputs that cause unintended operations in the application before someone else does.
Let’s say that there is a crash, though. After the crash has been triaged by the developer, meaning it has been located where it crashed and remediated, a developer can begin reworking this input into their testing flow. Remember, TDD is not inherently bad. However, with the use of FDD paired with it, software developers can create more robust unit tests for specific functionality of their code through the art of regression testing. In this case, regression testing is just a way to make sure any of the inputs that have previously caused a crash do not cause a crash later on in the project’s lifetime.
Where to go from here
What should you take away from this write-up? First and foremost, the understanding that fuzzing is no longer just for security researchers. Software developers, application users, and security enthusiasts have unfettered access to a myriad of different fuzzing utilities for many different use cases. Second, whether the use is in a development operations pipeline or to find vulnerabilities in your shiny new drone, fuzzing is a necessity that should be implemented whenever possible! Whether you use a dumb fuzzer or a smart one as we discussed, a fuzzer’s applicability and usefulness is unparalleled. Moving forward, look to see where you can use a fuzzer in your project to help assure your project is secure from even the most abstract user input. To learn more about fuzzing and how to successfully set up fuzzers, check out the references below. We’ll also be releasing a write-up in the near future on how to use and set up a fuzzer for your projects – so keep an eye open for that!
References
- https://about.gitlab.com/topics/application-security/what-is-fuzz-testing/
- https://owasp.org/www-community/Fuzzing
- https://searchsecurity.techtarget.com/definition/fuzz-testing
- https://forallsecure.com/resources/ultimate-guide-to-fuzz-testing
- https://github.com/google/fuzzing/blob/master/tutorial/libFuzzerTutorial.md
- https://www.f-secure.com/us-en/consulting/our-thinking/15-minute-guide-to-fuzzing
- https://blog.f-secure.com/super-awesome-fuzzing-part-one/
- https://labs.f-secure.com/blog/what-the-fuzz/
- https://arrow.tudublin.ie/cgi/viewcontent.cgi?article=1183&context=scschcomdis
- https://github.com/google/fuzzing/blob/master/docs/afl-based-fuzzers-overview.md
- https://google.github.io/clusterfuzz/

Subscribe to our blog
Be first to learn about latest tools, advisories, and findings.
Thank You! You have been subscribed.
Recommended Posts
You might be interested in these related posts.



