




TL;DR
AI doesn’t break STRIDE. It breaks the idea that systems have fixed roles. Agentic AI systems built on LLMs don’t behave like traditional components. They act like users, services, and data pipelines at the same time, often crossing trust boundaries. MAESTRO provides a layered way to model those risks across modern AI systems. In practice, you’ll end up using both—and treating AI agents like potential insider threats.
The STRIDE threat modeling approach was developed in the 1990s by Loren Kohnfelder and Praerit Garg at Microsoft and works well for conceptualizing threats to information systems. With the introduction of agentic AI and large language models (LLMs), however new architectural patterns have emerged that challenge traditional threat modeling assumptions.
The STRIDE framework breaks down for agentic AI because, for threat modeling purposes, an AI agent can act as multiple entities. It is a process but also a data store, dataflow, and an actor. While it is potentially a trusted internal actor for one process, it might be a potentially malicious external actor for another.
To address these complexities, AI researcher and author Ken Huang introduced the Multi-Agent Environment, Security, Threat, Risk and Outcome (MAESTRO) framework.
At first, this may feel complicated, but the following examples can help you determine when using the STRIDE framework is appropriate, when to deep dive into the MAESTRO framework, or when a blended approach would provide the most insight.
STRIDE and MAESTRO: Two Complementary Approaches
The STRIDE framework categorizes threats into six primary classes: spoofing, tampering, repudiation, information disclosure, denial of service, and elevation of privilege. STRIDE works particularly well for modeling threats across traditional application architectures where system components behave predictably and maintain clearly defined roles.
MAESTRO approaches the problem differently. Rather than focusing on threat categories, it models threats across the architectural layers that make up modern autonomous AI systems. These layers describe where threats may emerge as AI systems interact with data pipelines, models, external tools, and infrastructure.
Example Scenario: An Agentic AI Flight Booking System
To illustrate how these frameworks apply, consider a single-agent AI system designed to automate corporate travel booking. The system accepts prompts to purchase flights between destinations at the lowest price for a specific employee.
Example prompt: Purchase the cheapest flights between San Francisco and San Jose between January 20 and January 24 for John Smith.
To complete this task, the agent may have access to:
- External vendor APIs for flight booking
- Internal company approval workflows
- Internal company standards and policies
- Employee data for flight profiles
- A database of preferred vendors
The examples below demonstrate how the architecture of this system can evolve and how that evolution affects which threat modeling framework is most useful.
Example 1: When STRIDE Alone Works
In the simplest implementation, an organization may introduce a new agentic AI process that interacts with an existing internal data store but behaves similarly to a traditional application component.
In this scenario, the AI process accepts a user request and retrieves information from an internal data store that contains approved vendors and employee travel profiles. The system does not make autonomous decisions or interact with external services. Instead, it functions as a controlled interface between the user and the internal database.
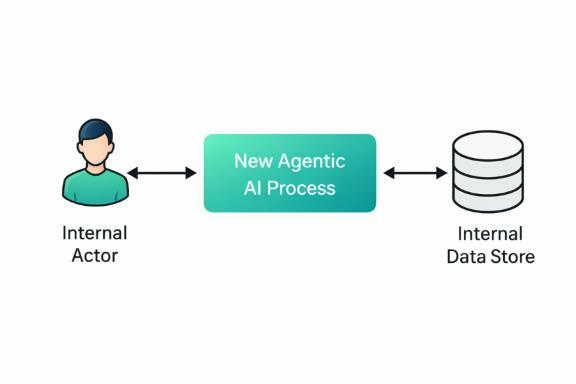
The AI process acts primarily as a processing layer that retrieves or submits data within an existing internal workflow. Because the architecture and system roles remain familiar, the threats introduced by this system can be evaluated using the STRIDE framework.
- Spoofing: The internal actor or agentic AI could spoof identity to the internal data store, or the internal actor could spoof their identity to the agentic AI process.
- Tampering: Either the agentic AI or internal actor could tamper with internal data store, or the internal actor or the agentic AI could tamper with data passed between the actor and process.
- Repudiation: Both the agentic AI and internal actor could deny accessing the data store or communicating with each other.
- Information Disclosure: The agentic AI or data flows could expose information to the internal actor from the data store.
- Denial of Service: The agentic AI could cause a denial of service of the data store, or the internal actor could cause a similar condition to the agentic AI or the internal data store.
- Elevation of Privilege: The agentic AI or internal actor could gain permissions beyond those intended. For example, if the AI process has broader access to the data store than required, or if authentication or authorization controls allow a users to perform actions outside their normal role.
In this example, switching out the agentic AI process with a standard process doesn’t materially change the threats. STRIDE works well here because the system behaves like a traditional software component within an internal architecture.
Example 2: When MAESTRO Becomes Necessary
As AI systems become more autonomous, their architecture expands beyond simple internal processes. Consider an evolution of the same flight booking system. Instead of simply retrieving data, the tool now has access to external vendor APIs, internal company approval flow, internal company standards, internal company employee data for flight profile, and a database of preferred vendors.
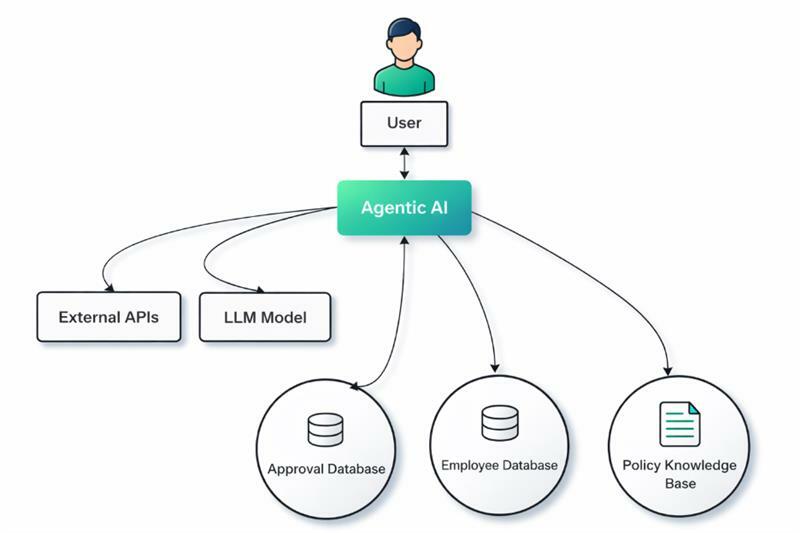
The MAESTRO framework works well in this example because it helps analyze threats across the seven architectural layers that make up modern autonomous AI systems. Let’s look at it in context of our booking system scenario.
(L1) Foundation Models Denial of Service
Threat: The computational resources provided to the agentic AI are insufficient to meet the end user demand.
Scenario: The booking agent resources are correctly scoped for the development environment, but when moved to a production environment, the number of requests from end users causes the system to become unusable.
Mitigation: Attackers consume all of the compute resources resulting in end users experiencing a denials of service. Additionally, depending on the compute resources in use this could increase cost for the company significantly.
Common Threats
- Adversarial Examples
- Model Stealing
- Backdoor Attacks
- Membership Inference Attacks
- Data Poisoning (Training Phase)
- Reprogramming Attacks
- Denial of Service (DoS) Attacks
Data Operations (L2) Agent Memory Poisoning
Threat: An attacker compromises the agent's short-term or long-term memory to alter its preferences or behavior.
Scenario: The booking agent references vendor data and company policy documents when selecting flights. If malicious text is inserted in a vendor or company file poisoning the memory, the agent can be manipulated to believe Vendor A is preferred over the actual company-approved vendor or an approval has been granted when it has not. This could lead the system to consistently prioritize that vendor even though it does not meet company policy requirements.
Mitigation: Sanitize and validate all data read from external sources; implement read-only memory for business-critical configuration files.
Common Threats
- Data Poisoning
- Data Exfiltration
- Denial of Service on Data Infrastructure
- Data Tampering
- Compromised RAG Pipelines
Agent Frameworks (L3) Execution Logic and Workflow Control
Threat: The underlying foundational model or libraries are malicious, unfit for purpose, or unsupported.
Scenario: The booking agent relies an open-source library to interpret prompts, retrieve employee travel profiles, and query vendor flight APIs. If that has been compromised, it could allow for remote code execution on the server hosting the booking agent.
Mitigation: Regular vulnerability scanning of dependencies and using signed, reputable models.
Common Threats
- Compromised Framework Components
- Backdoor Attacks
- Input Validation Attacks
- Supply Chain Attacks
- Denial of Service on Framework APIs
- Framework Evasion
Deployment and Infrastructure (L4) Tool/Plugin Misuse
Threat: The container or virtual machine hosting the agent is compromised
Scenario: An attacker compromises the cloud instance running the flight booking agent and gains access to the API keys used to communicate with external flight vendors. The attacker could then submit unauthorized flight purchases directly through the vendor APIs.
Mitigation: Use secrets management services (e.g., HashiCorp Vault, AWS Secrets Manager) for API keys, never hardcode credentials. Appropriately harden containers and infrastructure.
Common Threats
- Compromised Container Images
- Orchestration Attacks
- Infrastructure-as-Code (IaC) Manipulation
- Denial of Service (DoS) Attacks
- Resource Hijacking
- Lateral Movement
Evaluation and Observability (L5) Data Handling & Privacy
Threat: The agent leaks confidential information during its operations.
Scenario: While attempting to find the best flight price, the booking agent sends a request to a vendor API that includes sensitive employee or company travel data, exposing confidential information outside the organization.
Mitigation: Data loss prevention (DLP) filters to scan outputs for sensitive data (PII, IP). Explicitly restrict agent from using data fields and monitor logging and event management systems for inadvertent exposure.
Common Threats
- Manipulation of Evaluation Metrics
- Compromised Observability Tools
- Denial of Service on Evaluation Infrastructure
- Evasion of Detection
- Data Leakage through Observability
- Poisoning Observability Data
Security and Compliance (L6) Infrastructure & Deployment
Threat: The agent is over-privileged and uses its tools to act maliciously.
Scenario: The booking agent has access to internal employee travel profiles and approval data. If the agent is over-privileged, it could alter information for flight preferences or approvals.
Mitigation: Apply the principle of least privilege. The agent access should be granted read access to necessary files and read/write to defined processes.
Common Threats
- Security Agent Data Poisoning
- Evasion of Security AI Agents
- Compromised Security AI Agents
- Regulatory Non-Compliance by AI Security Agents
- Bias in Security AI Agents
- Lack of Explainability in Security AI Agents
- Model Extraction of AI Security Agents
When thinking about Layer 6 it is important to conceptualize it a a vertical layer, unlike the other horizontal layer. This vertical layer affects all of the other layers since it integrates security and compliance into the environment. This is a fairly standard concept where security is applied at all layer in a defense in depth approach.

Agent Ecosystem (L7) Ecosystem & Supply Chain
Threat (A): The agent interprets "cheapest flight" as purchasing flights that do not adhere to company standards, a malicious vendor prompt tricks the agent into using a more expensive option to fulfill the "cheapest" goal.
Scenario (A): The agent misinterprets elements of the travel request. For example, the purchases flights for the incorrect employee, the agent correctly interprets San Francisco and San Jose but does not purchase flights for the correct US cities, or the agent interprets January 20th correctly but does not purchase flights for the current year due to future dates being less expensive.
Mitigation (A): Define strict, non-negotiable boundaries ("Do not spend more than $250/flight" or "Only buy flights from approved vendors"). Require strict input clarification (EmployeeID or Years) for ambiguous prompts.
Threat (B): Prompt injection or malicious API responses alter the agent's behavior.
Scenario (B): A flight vendor's website sends back a specially crafted JSON response that acts as a prompt injection, telling the booking agent to ignore approval steps.
Mitigation (B): Strict input/output validation. Sanitize all data coming from external APIs before passing it to the LLM.
Common Threats
- Compromised Agents
- Agent Impersonation
- Agent Identity Attack
- Agent Tool Misuse
- Agent Goal Manipulation
- Marketplace Manipulation
- Integration Risks
- Horizontal/Vertical Solution Vulnerabilities
- Repudiation
- Compromised Agent Registry
- Malicious Agent Discovery
- Agent Pricing Model Manipulation
- Inaccurate Agent Capability Description
The MAESTRO framework helps surface threats that emerge as the booking agent interacts with models, data pipelines, infrastructure, and external services. This deeper view highlights risks that may not appear when analyzing the system solely as a traditional application.
Example 3: Blending the Models
When the booking agent is deployed into a broader enterprise environment, the threat model expands beyond the technical components of the AI system itself. The system now includes multiple actors interacting across internal systems, external services, and trust boundaries.
The blended threat model shown in the diagram below combines elements from the first two examples into a simplified image. Included in the image are red arrows which indicate a threat that was introduced, so that it can be discussed later. Some details are also left out for the ease of discussion, such as implementation details of RAG access, LLM guardrails, and firewalls.
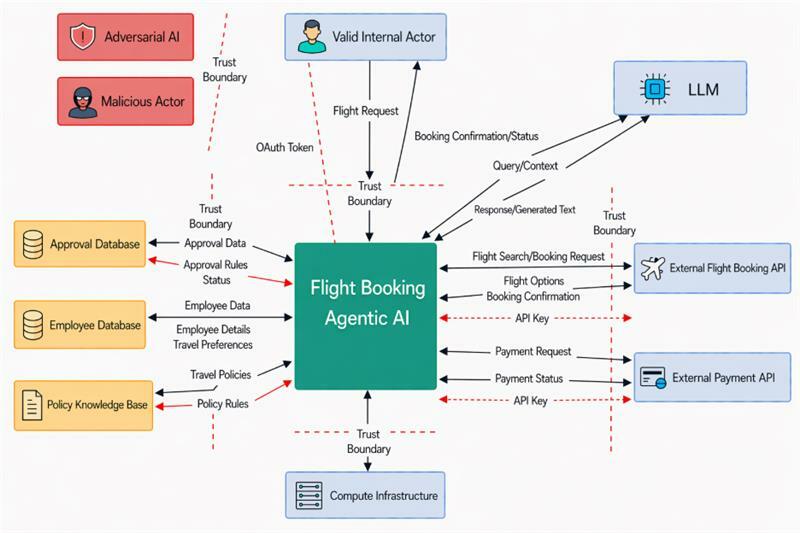
The main difference between relying solely on either STRIDE or MAESTRO that significantly changes the threat models is the inclusion of actors and trust boundaries. Trust Boundaries are a way of mentally dividing threats into different levels. All items on the untrusted side of a trust boundary may be considered as having a higher risk than those on the trusted side.
In this scenario, three primary actor types interact with the booking agent (Valid Internal Actor, Adversarial AI, and Malicious Actor) significantly increasing the complexity of the threat model.
- Valid Internal Actor can make mistakes or cause issues with the booking agent because of simple errors like an invalid token, errors in the employee or approval databases, or simple typos. For example, in a large company with employees across different countries, the difference between the DD/MM/YYYY and MM/DD/YYYY date formats could result in a correct flight being booked based on the model input, but lead to a loss of confidence in the agent because the result did not match the user’s expectation.
- Adversarial AI, in this scenario, could appear in a few different areas. For example, a flight booking company could configure its API responses in a way that attempts to influence the agent’s behavior. By shifting costs from the ticket price to additional fees, the vendor could attempt to coerce the flight booking agent into selecting more expensive options while still appearing to satisfy the “cheapest flight” goal
- Malicious Actor could be internal or external and attempts to compel the booking agent to act in a way that is counterproductive or incorrect. These actors may attempt to manipulate prompts, exploit system integrations, or use the agent to compromise other connected systems or data sources.
As such, some organizations have applied a zero-trust approach when threat modeling their in-house agentic AI applications and start their threat modeling from the assumption that their internal AI agents are considered insider threats.
For specific examples that we included in the diagram above, the agentic AI has been given read/write access to the approval database. For the MAESTRO framework, this is a Layer 4 issue because the agent has excessive permissions and can potentially be coerced into either granting an approval that is unauthorized or changing approval conditions. This can also be considered a data tampering threat from the STRIDE model. Similarly, an issue with excessive privileges to the policy knowledge base could allow the agent to alter or disclose a policy on behalf of a malicious external flight booking API AI.
Final Thoughts
When performing threat modeling, it is best not to get bogged down in conceptual models but to understand the risk appetite and overall impact. The perfect threat model assessment is the one that improves the environment, not the one that most closely adheres to a single framework. While the macro view that STRIDE takes is good for looking at the entire ecosystem an agentic AI might exist in, MAESTRO is the right tool for a deep dive and uncover the real and specific threats that AI introduces or is exposed to. Using both approaches together can provide a more complete understanding of how threats may emerge across modern AI-enabled environments.
For organizations deploying agentic AI systems, this flexibility is critical. Treating AI agents as potential actors within the threat model, and understanding how they interact with users, infrastructure, and external services, helps teams identify risks that may not appear when using traditional application security models alone.
At Bishop Fox, we approach threat modeling in the same way: focusing less on rigid adherence to a single framework and more on identifying the threats that matter most for the system being built. By applying the right model, or combination of models, to the right problem, security teams can better understand how modern AI systems behave and where their real risks lie.
Discover Bishop Fox’s threat modeling methodology.
More Reading for Real World AI Threat Modeling
Foundational AI Threat Modeling Documents
- Threat Modeling in the Wild, Ken Huang, Medium
- MAESTRO Threat Modeling Guides, Cloud Security Alliance
- MAESTRO Reference Document, Ken Huang, Medium
- OWASP Threat Modeling Guide, GenAI OWASP

Subscribe to our blog
Be first to learn about latest tools, advisories, and findings.
Thank You! You have been subscribed.
Recommended Posts
You might be interested in these related posts.



