Quick Summary (TLDR)
Cirro starts from a simple idea: cloud risk usually lives in relationships, not isolated objects. A user, a role assignment, a resource scope, a managed identity, a secret, and a downstream application programming interface (API) permission may each look fine on their own, but if you put them together, then you have an attack path.
That is what Cirro is built to show. It builds a graph that links identity, permissions, resources, and data-plane context. Under the hood, it does that with a schema engine using Tera templates, YAML files, and shared constants to describe how data should turn into nodes and relationships. This is why Cirro can grow across Azure without turning every new resource type into a custom ingestion project.
Repositories
Attacks Paths Can Be Complex
Let's start with an understanding of attack paths.
Single permissions rarely look scary in isolation. The trouble starts when one permission belongs to an identity, that identity inherits more access through a group, that access applies at a specific scope, and that scope leads to a resource with its own identity, secret, or service permissions. The issue is not one object but the entire chain.
A simple example is a user moving through group membership, role-based access control (RBAC), a resource group, a virtual machine (VM), a managed identity, a Key Vault role, and finally the Key Vault itself. Each hop makes sense by itself. The danger shows up when you can see the whole route at once.

This is a pretty standard representation of a common attack path in Azure. However, Cirro’s management plane analysis goes a bit further. For example, a virtual machine contains disks, network interface cards, a private IP that is part of a subnet, and sometimes a public IP. Cirro aims to maximize the attack path potential by also looking at the configurations associated with any given resource. For example, the image above can be expanded to show those details about the virtual machine:
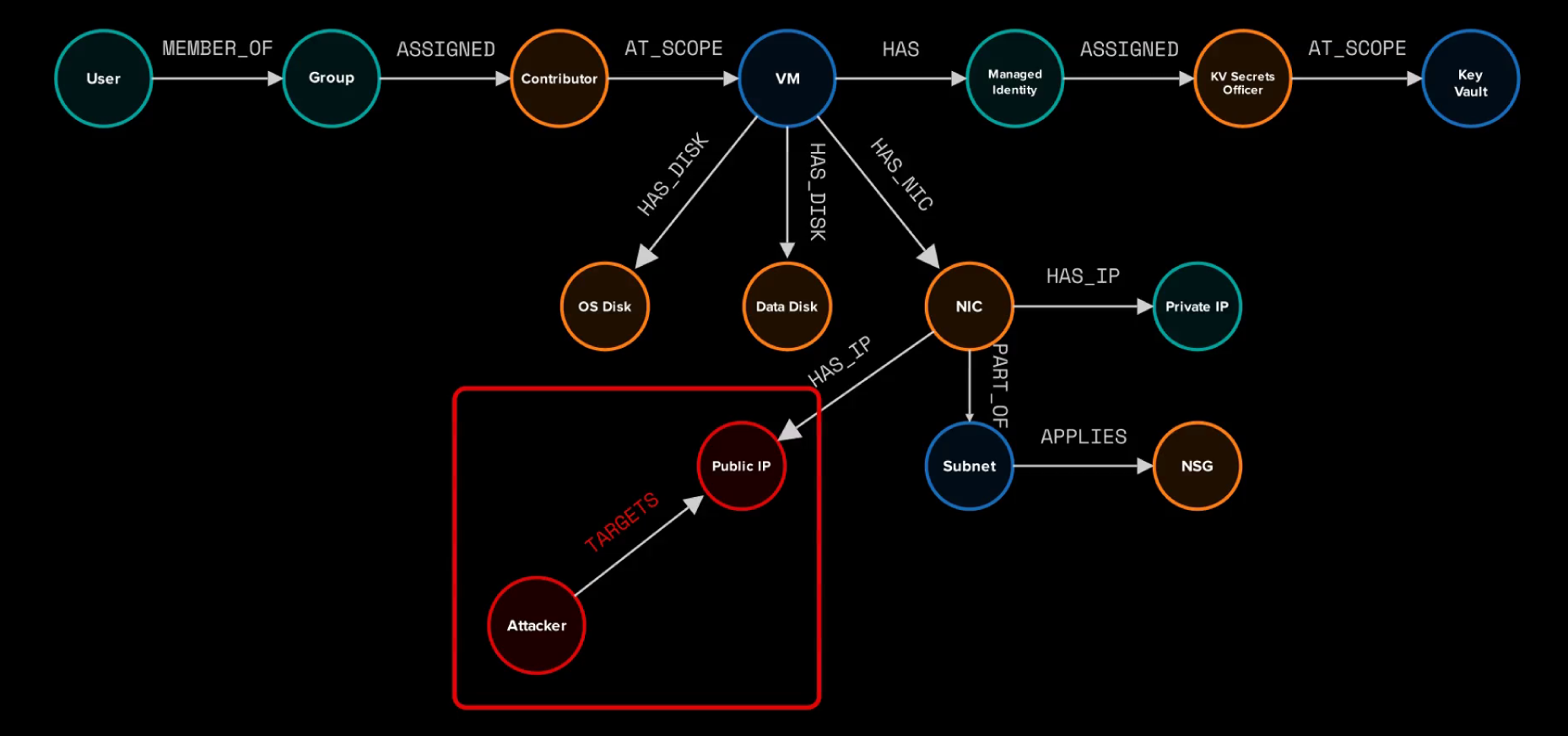
The attack path from the user’s group membership certainly exists. But what if the Virtual Machine is hosting an exploitable application on its public IP? We would also need to consider that the exploitable application may be a way to access the target Key Vault if the attacker can obtain an access token for the Managed Identity.
That is why the graph matters. It is not just a prettier asset inventory. It gives you a way to ask who has access, where it applies, and what that access can lead to next.
Why Cirro Exists
There are already great cloud tools, but they usually lean toward one part of the problem. Some are good at management-plane collection. Some are good at directory enumeration. Some are good at browsing data after it is already in a graph. What is still hard is tracing attack paths across cloud identity, RBAC, resources, and deeper service context in one place.
Cirro exists to close that gap. It is built for mapping and analyzing cloud environments in a way that helps answer a simple question: What can this identity actually reach, control, or abuse once all the relationships are connected?
To assist in this analysis, Cirro has an additional focus on the data plane.
Why the Data Plane Matters
If you only model the management plane, you can answer a lot of useful questions about identities, RBAC, scopes, and resources. That is a solid start. It is not the whole picture.
A Key Vault example makes the gap easier to see. Once Cirro can model the data plane as well, the graph can include secrets, certificates, and the identities tied to them. At that point, the graph is not just telling you who can administer a resource. It is also helping you reason about what that administration might expose downstream. This can assist in identifying scenarios where development and production secrets and identities are being used interchangeably. Let’s look at the following real scenario (in which nodes are being shown by their labels to avoid client attribution):
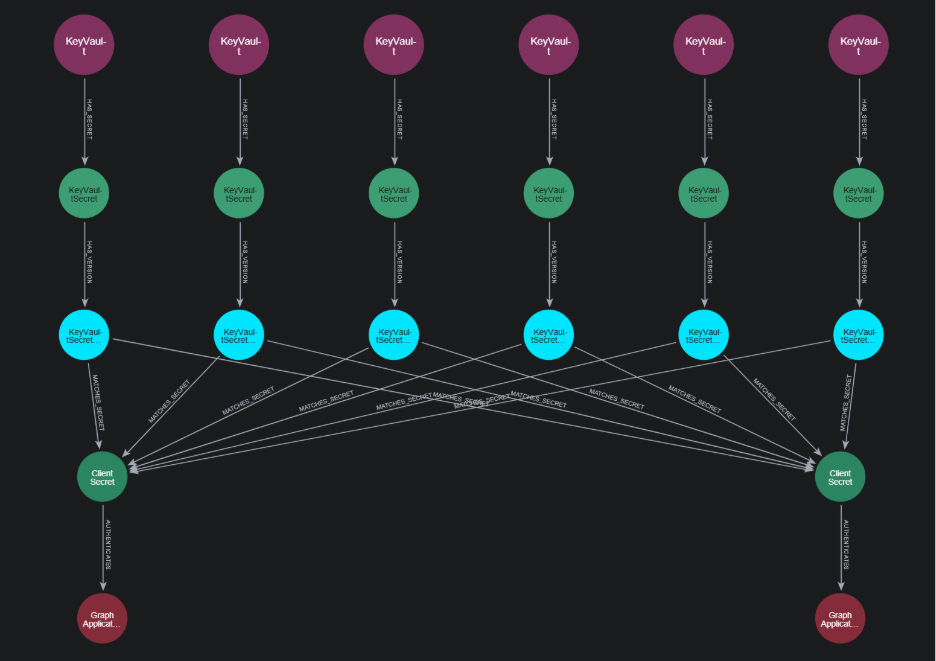
In this example, we have five Key Vaults. Although the names are not shown here, each of these Key Vault are labeled for distinct environments: two dev, two QA, one staging, and one prod. Each of these Key Vaults contains a client secret that Cirro has identified is used to authenticate one of two potential Entra ID Applications. Although Cirro does not perform any validation itself, we can create the MATCHES_SECRET relationship based on the contents of the secret itself and the publicly known client secret hint, which contains the first three characters of the secret. This is a loose correlation, since comparing three characters has a lot of potential for collisions. However, we can use additional context clues to identify the correct client secret credential. For example, we can look at the names of the secret and the application itself. Or we can attempt to loosely correlate the client secret creation time with the key vault secret creation time. In this case, the five Key Vaults contain a secret for the Entra ID application on the bottom right.
However, a bigger question emerges: Why are the development, QA, staging, and prod environments for this application using the same identity? Development environments are often less secure than production environments, and best practices would include having separate identities for each environment.
This is the kind of scenario that Cirro can unearth during attack path analysis.
Cirro Tool Suite
Cirro is the suite of tools designed to help collect information, ingest, and analyze attack path data:
- Cirro is the core command-line interface (CLI). It collects data, normalizes it, and ingests it into a graph.
- CirroDash is the analysis and dashboard layer for exploring Neo4j data and running prebuilt analysis modules.
cirro-azcli-extis an Azure CLI extension that passively captures API responses during real command usage and stores them in a Cirro-compatible SQLite database.
The cirro-azcli-ext is especially useful since it leads to being able to identify useful data plane items that can expand the graph. Currently, only Key Vault Secrets and Certificates are included. However, any data plane resource could be added to Cirro, such as Storage Account blobs and containers, Service Bus topics, Azure Backup containers, Azure Container Registry containers, etc.
How the Schema Engine Works
Cirro does not hard code every Azure resource into the binary. Instead, it splits the job into a few reusable pieces:
constants.yamlholds shared graph vocabulary such as node labels and relationship names**/*.tera.yamlfiles describe source handling using (YAML) with Tera templating- Cirro binary loads the rendered templates into typed spec structures and executes them
For example, the schema that represents an Azure Key Vault looks like this:
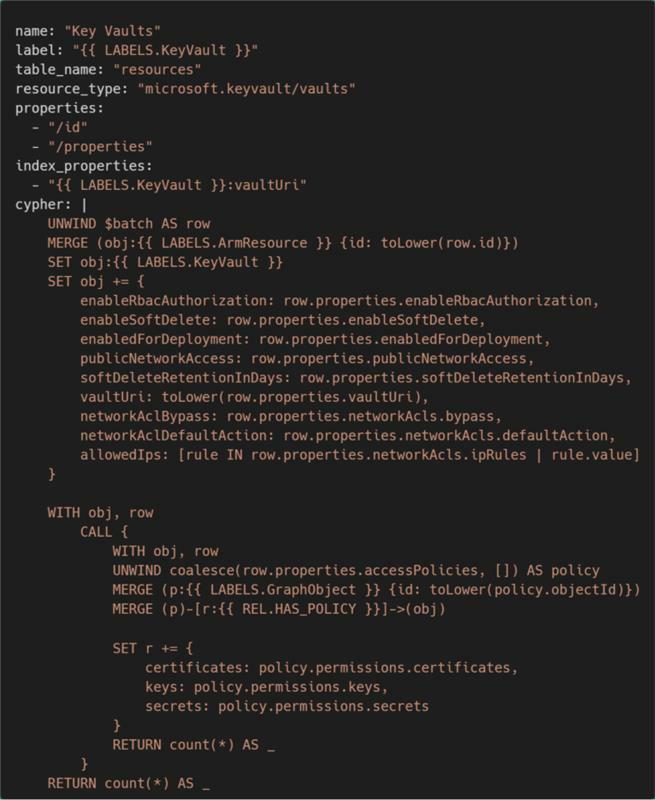
The core idea is that Tera renders the template with YAML files that implement the spec. Rust loading stays generic and runs the result. You do not need a separate code path in the binary for every Azure resource family.
You’ll notice conditional logic in the Cypher blocks of many YAML schemas. It’s pretty common for a lot of API responses from ARM HTTP requests to not return all of the attributes of the spec, therefore, the Cypher patterns used in Cirro provide some validity checks for certain attributes. In the Key Vault example, if the accessPolicies property exists, then we can create a relationship with an identity from Entra ID to the Key Vault and include the access policies. However, with access policies being deprecated, this property may not exist in the future. The conditional check with coalesce allows us to process a Key Vault whether it has legacy access policies or uses Azure RBAC.
Let’s Get all the Resources
Not every Azure resource type has a dedicated schema for ingestion. Cirro still ingests those resources generically. The reason is that an attack path still matters even when the resource type is not deeply modeled. RBAC can apply at the resource scope. If a path exists in Azure, the attack graph should know that it exists, even if the node is only represented in a generic way for now. That means the graph can still preserve reachability and scope information while more detailed schemas are added over time.
Post-Processing
Post-processing is another part of the design that’s important for improving the representation of the attack graph. These modules are also declarative, but they run after every ingestion instead of being tied to one specific source. That gives Cirro a place for graph-wide cleanup and enrichment. Normalization, deduplication, and relationship refinement can happen in one consistent layer instead of being copied into every individual schema. This design keeps the per-source specs focused. Each schema can describe how to map source data into the graph, while post-processing handles the cleanup that applies everywhere.
What Extensibility Looks like in Practice
For Azure, extensibility is pretty straightforward. If you want to support another resource type, you usually add a new template, add constants if you need them, and let the existing loader and Azure runtime handle the rest.
If you want to go beyond Azure, the work is bigger, but the boundary is still clear. You add a new spec type, extend the registry and ingest selector, and plug in a processor for that family. That is a much better place to be than scattering platform-specific logic all over the codebase, and it ensures that any built-in extensions can use the same nodes and labels as other extensions.
Conclusion
Cirro is interesting because it connects two things that are often separated.
The first is the problem space: attack paths are about relationships between identities, permissions, scopes, resources, and, increasingly, data-plane artifacts. The second is the implementation: a templated YAML-driven schema gives Cirro a way to keep growing without turning every new data source into a one-off project.
With this existing implementation, Azure is just the start. In future Inside Cirro content, we’ll provide general updates and discuss useful queries that will help you to gain a better understanding of attack paths across the management and data planes.
Other tools to consider
Resources

Subscribe to our blog
Be first to learn about latest tools, advisories, and findings.
Thank You! You have been subscribed.
Recommended Posts
You might be interested in these related posts.